Topic Modeling Definition of Nature
Topic Modeling
https://cran.r-project.org/web/packages/topicmodels/vignettes/topicmodels.pdf
These are “mixed-membership models” (see [1]). This assumes that definitions (in the case of this analysis) can belong to several topics and that the topic distribution can vary across definitions. This differs to other models (such as Semantic Analysis) which assumes that each word comes from the same distribution - that is, it is just as likely for a given word to appear in any one definition.
Two models can be used:
Latent Dirichlet Allocation (LDA) - this is a Bayesian mixture model when it is assumed that topics are uncorrelated (this would not be the case in this analysis)
Correlated Topics model (CTM) - extends upon LDA by allowing correlations between the topics
(see [2] and [3] for intros to these models)
Correlated Topics Model
This analysis uses the topicmodels package which uses the VEM (variation expectation-maximization) algorithm.
Preprocessing
- Each row = participant
- Each column = word
- convert to lower case
- remove punctuation
- remove numbers
- stemming (removing prefixes and suffixes)
- removing stop words
- removing words below a certain length minimum
- Optional: select only words that occur in a minimum number of definitions (see [4])
- Optional: select terms which highest term-frequency inverse document frequency (tf-idf) scores (see [3]) - this is only used for selecting the vocabulary in the corpus
Fitting the Model
In the CTM you fix the number of topics (k) a-priori. In this analysis I ran the model fixed at both 14 (the number of categories identified during manual coding) and 7 (the higher-order topics that each of these categories fit into).
“Additionally, estimation using Gibbs sampling requires specification of values for the parameters of the prior distributions. [4] suggest a value of 50/k for α and 0.1 for δ. Because the number of topics is in general not known, models with several different numbers of topics are fitted and the optimal number is determined in a data-driven way.”
Selecting the number of topics can be done by splitting the data into training and testing sets. ” The likelihood for the test data is then approximated using the lower bound for VEM estimation.”
“Another possibility for model selection is to use hierarchical Dirichlet processes as suggested [5]”.
Topic modelling uses a probabilistic algorithm to calculate the probability of a word appearing given a particular topic (category of definition)
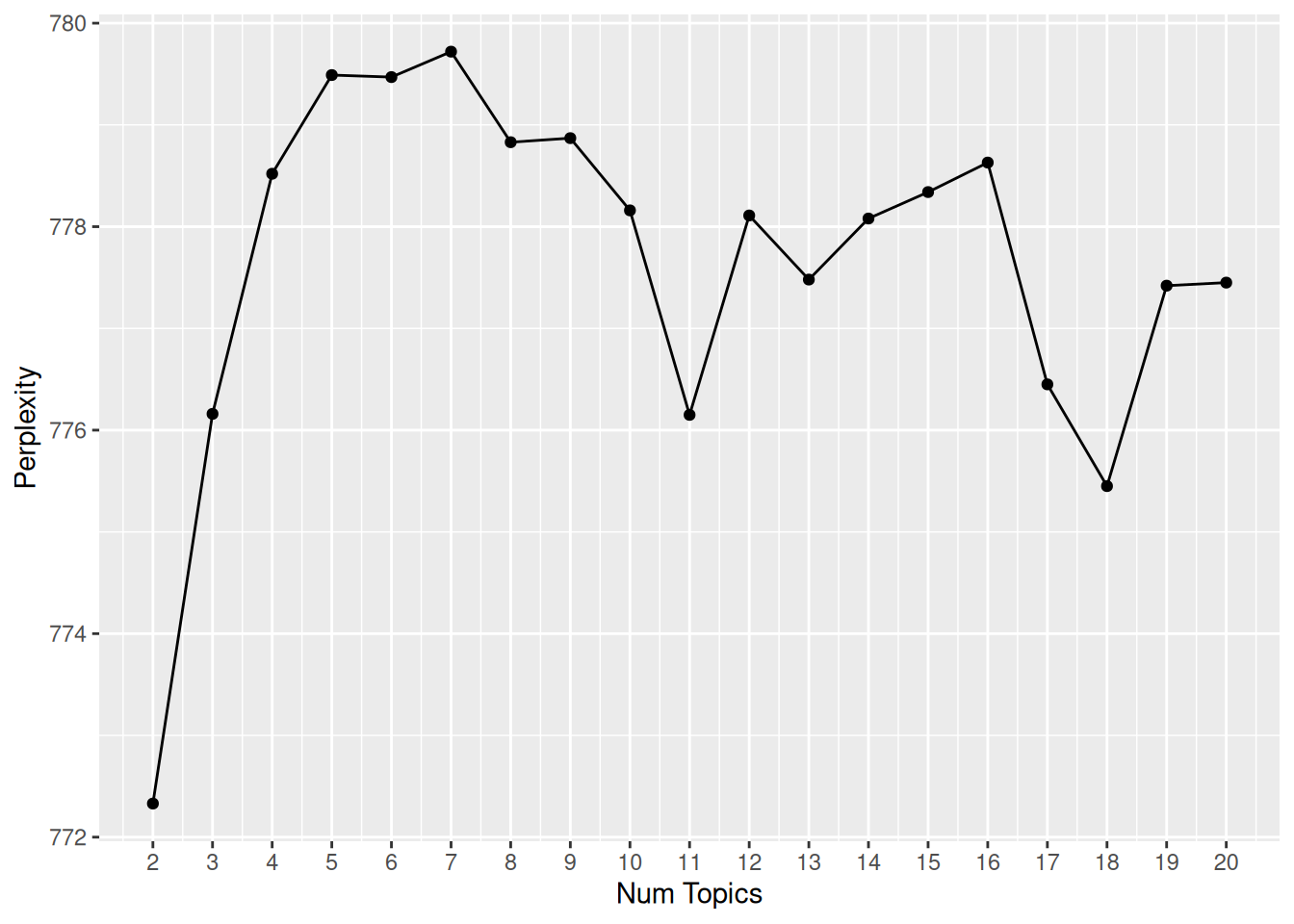
Perplexity of models given varying amounts of topics | |||
|---|---|---|---|
Num Topics | LogLik | Perplexity | Themes |
2 | -59381.9503174082 | 772.326437265421 | natur, anim |
3 | -59421.5592366393 | 776.164516674393 | plant, anim, natur |
4 | -59442.0295455392 | 778.518088140724 | plant, anim, natur, earth |
5 | -59446.6197440542 | 779.4854042851 | outdoor, anim, natur, earth, world |
6 | -59445.1615487207 | 779.468312805306 | plant, anim, tree, earth, plants_anim, natur |
7 | -59448.3613681738 | 779.724657438038 | outdoor, anim, tree, earth, plants_anim, environ, natur |
8 | -59439.8127945491 | 778.830509353136 | outdoor, anim, everyth, earth, plants_anim, environ, forest, natur |
9 | -59440.8107295069 | 778.865172591979 | outdoor, anim, around_us, thing, plants_anim, without, forest, outsid, earth |
10 | -59427.1546790232 | 778.156239975586 | outdoor, anim, everyth, plant, plants_anim, without, forest, outsid, earth, tree |
11 | -59423.0705650545 | 776.153599507428 | outdoor, anim, around_us, plant, plants_anim, without, forest, outsid, earth, live, natur |
12 | -59421.6136498809 | 778.111006218198 | outdoor, anim, around_us, plant, plants_anim, without, forest, outsid, earth, live, environ, natur |
13 | -59422.6977120152 | 777.47886099978 | outdoor, anim, around_us, thing, around, without, man, exist, earth, live, environ, world, natur |
14 | -59421.6979283443 | 778.077493546316 | outdoor, live, around_us, thing, natur, without, man, exist, earth, life, environ, world, anim, plant |
15 | -59419.8811201895 | 778.343854648547 | outdoor, live, around_us, thing, around, without, man, exist, earth, life, environ, world, anim, area, natur |
16 | -59420.2245459775 | 778.629073395814 | outdoor, live, around_us, thing, around, without, man, exist, earth, life, environ, world, anim, tree, plants_anim, natur |
17 | -59407.2209355495 | 776.453640798642 | outdoor, part, around_us, plant, natur, without, man, exist, earth, life, environ, world, anim, area, plants_anim, live, natur |
18 | -59403.9166452776 | 775.449449888357 | outdoor, part, around_us, plant, natur, without, man, exist, earth, tree, environ, world, anim, forest, plants_anim, live, natur, natur |
19 | -59407.0185773046 | 777.424100007218 | outdoor, part, around_us, plant, natur, without, man, exist, earth, life, wildlif, world, anim, forest, plants_anim, live, natur, environ, natur |
20 | -59395.371028869 | 777.45481758584 | outdoor, part, around_us, plant, physic, without, man, exist, earth, life, wildlif, world, anim, tree, plants_anim, live, natur, environ, someth, tree |
After going through all of this work, I do not think that this is a useful way of categorizing definitions. There is too much complexity in the way that people use synonyms in order for the algorithm to detect probabilistically what their definition should be categorized as.
Airoldi EM, Blei DM, Fienberg SE, Xing EP (2008). “Mixed Membership Stochastic Block- models.” Journal of Machine Learning Research, 9, 1981–2014.
Steyvers M, Griffiths T (2007). “Probabilistic Topic Models.” In TK Landauer, DS McNamara,S Dennis, W Kintsch (eds.), Handbook of Latent Semantic Analysis. Lawrence Erlbaum Associates.
Blei DM, Lafferty JD (2009). “Topic Models.” In A Srivastava, M Sahami (eds.), Text Mining: Classification, Clustering, and Applications. Chapman & Hall/CRC Press.
Griffiths TL, Steyvers M (2004). “Finding Scientific Topics.” Proceedings of the National Academy of Sciences of the United States of America, 101, 5228–5235.
Teh YW, Jordan MI, Beal MJ, Blei DM (2006). “Hierarchical Dirichlet Processes.” Journal of the American Statistical Association, 101(476), 1566–1581
https://heartbeat.comet.ml/text-classification-using-machine-learning-algorithm-in-r-ba763117c8aa